Ziel der deskriptiven Statistik ist es, einen Überblick über die vorliegenden Daten zu erhalten, diese zu ordnen und zusammenzufassen.
Es geht in der deskriptiven Statistik also um das Beschreiben von Daten und die Ergebnisse beziehen sich dabei immer direkt auf den vorliegenden Datensatz.
MerkeNeben der deskriptiven Statistik gibt es noch die induktive Statistik (auch Inferenzstatistik genannt). Hierbei werden Aussagen über einen Datensatz hinaus getroffen, indem von einer Stichprobe auf eine Grundgesamtheit geschlossen wird.
Zusammenhangsmaße werden verwendet, um die Stärke eines statistischen Zusammenhangs zwischen zwei Variablen anzugeben.
Einige Zusammenhangsmaße geben darüber hinaus auch Auskunft über die Richtung des Zusammenhangs.
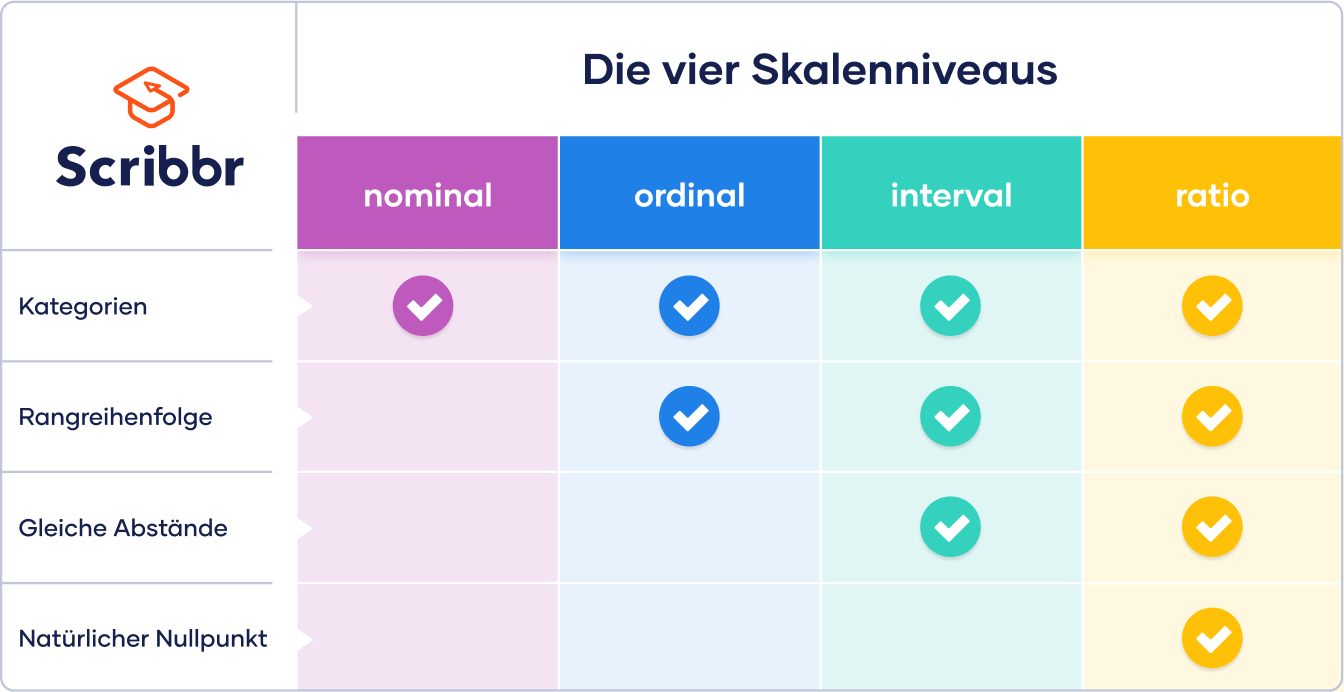
Welches Zusammenhangsmaß du verwenden kannst, hängt vom Skalenniveau deiner Daten ab.
BeispielWir wollen den Zusammenhang zwischen der Entfernung zwischen Wohn- und Arbeitsort und der Dauer des Arbeitsweges bestimmen. Wir haben also metrische Daten vorliegen und bestimmen daher als Zusammenhangsmaß den Korrelationskoeffizienten nach Pearson.
Cramers V gibt Auskunft über den statistischen Zusammenhang zwischen zwei oder mehreren nominalskalierten Variablen.
Der Wert 0 bedeutet, dass es keinen statistischen Zusammenhang gibt.
Der Wert 1 bedeutet, dass es einen perfekten statistischen Zusammenhang gibt.
In der Praxis liegt Cramers V normalerweise zwischen 0 und 1.
Bei der Bestimmung von Cramers V wird der Chi-Quadrat-Wert (X2) standardisiert. Dadurch kannst du Zusammenhänge zwischen Variablen anhand von Cramers V vergleichen.
Den Rangkorrelationskoeffizient nach Spearman wird verwendet, um den Zusammenhang zwischen zwei mindestens ordinalskalierten Variablen zu bestimmen.
Anhand des Rangkorrelationskoeffizienten können wir Aussagen darüber treffen, ob zwei Variablen zusammenhängen, und wenn ja, wie stark der Zusammenhang ist und in welche Richtung er besteht.
Der Rangkorrelationskoeffizient nach Spearman wird auch als Spearman‘s Rho () bezeichnet.
Der Korrelationskoeffizient nach Pearson, auch Korrelationskoeffizient nach Bravais-Pearson genannt, gibt uns Auskunft über den Zusammenhang von zwei metrisch skalierten Variablen.
BeispielWir möchten bestimmen, ob ein Zusammenhang zwischen der Größe und dem Gewicht von Personen besteht und wie stark dieser Zusammenhang ist.
Da es sich um einen standardisierten Koeffizienten handelt, können wir Zusammenhänge anhand des Korrelationskoeffizienten miteinander vergleichen.
Veröffentlicht am
12. Juni 2020
von
Valerie Benning.
Aktualisiert am
30. Januar 2025.
Chi-Quadrat χ2 gibt dir Auskunft über den Zusammenhang von zwei nominal– oder ordinalskalierten Variablen.
BeachteDa es sich beim Chi-Quadrat-Koeffizienten um ein nicht-standardisiertes Zusammenhangsmaß handelt, ist nur eine begrenzte Interpretation möglich.
Veröffentlicht am
7. Mai 2020
von
Valerie Benning.
Aktualisiert am
9. April 2023.
Skalenniveaus sind Kategorien, die uns eine Auskunft darüber geben, welche Merkmale unsere Daten aufweisen.
Deine Daten können entweder nominalskaliert, ordinalskaliert, intervallskaliert oder ratioskaliert sein.
Dabei haben metrische Daten den höchsten Informationsgehalt und erlauben die meisten Berechnungen. Nominalskalierte Daten haben dagegen die geringste Aussagekraft.
In der deskriptiven Statistik bezeichnet ‘Streuung’ die Verteilung von Daten und gibt an wie weit die einzelnen Werte innerhalb eines Datensatzes gestreut sind.
Die Streuung unserer Daten können wir in Streuungsmaßen angeben.
 ) bezeichnet.
) bezeichnet.