Deskriptive Statistik verstehen und anwenden
Ziel der deskriptiven Statistik ist es, einen Überblick über die vorliegenden Daten zu erhalten, diese zu ordnen und zusammenzufassen.
Es geht in der deskriptiven Statistik also um das Beschreiben von Daten und die Ergebnisse beziehen sich dabei immer direkt auf den vorliegenden Datensatz.
Kennzahlen in der deskriptiven Statistik mit Beispielen
Zum Beschreiben der Daten werden vor allem drei Kennzahlen verwendet: Streuungsmaße, Lageparameter und Zusammenhangsmaße.

Nehmen wir an wir haben zehn Personen nach ihrer Körpergröße gefragt und die folgenden Antworten erhalten:
| Person | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Körpergröße in cm | 180 | 165 | 172 | 165 | 187 | 192 | 158 | 165 | 180 | 156 |
Zur Bestimmung der Parameter wissen wir also bereits: n = 10.

Lageparameter
Lageparameter werden in der deskriptiven Statistik verwendet, um die zentrale Lage einer Verteilung von Daten anzugeben, also zum Beispiel den Mittelwert oder den Zentralwert.
Die wichtigsten Lageparameter sind
- das arithmetische Mittel
- der Modus
- der Median
Arithmetisches Mittel
Das arithmetische Mittel (auch Mittelwert) beschreibt den statistischen Durchschnittswert deiner Daten.
Zur Berechnung addieren wir alle Beobachtungsdaten und teilen dann die Summe durch die Anzahl der Daten.
Berechnung:

Die durchschnittliche Größe der befragten Personen beträgt 172 cm.
Modus
Der Modus (auch Modalwert) ist der Wert, der in einem Datensatz am häufigsten vorkommt.
| Körpergröße | 156 | 158 | 165 | 172 | 180 | 187 | 192 |
|---|---|---|---|---|---|---|---|
| Häufigkeit | 1 | 1 | 3 | 1 | 2 | 1 | 1 |
Der Modus der befragten Personen liegt bei 165 cm. Diese Körpergröße kommt am häufigsten in den Beobachtungsdaten vor.
Median
Der Median (auch Zentralwert) ist der Wert, der genau in der Mitte einer Datenreihe liegt, die nach der Größe geordnet ist.
Berechnung:
geordnete Reihe: 156, 158, 165, 165, 165, 172, 180, 180, 187, 192

Der Median liegt bei 168.5 cm. Diese Körpergröße liegt genau in der Mitte der geordneten Datenreihe und teilt die Gruppe in zwei Hälften.
Streuungsmaße
Streuungsmaße werden in der deskriptiven Statistik verwendet, um die Verteilung und die Streubreite von Daten anzugeben.
Zu den Streuungsmaßen zählen
- die Varianz
- die Standardabweichung
- die Spannweite
Varianz
Die Varianz gibt an, wie sich deine Beobachtungswerte um den Mittelwert aller Beobachtungen verteilen.
Berechnung:

Die Varianz beträgt 150.22 (cm2).
Standardabweichung
Die Standardabweichung ist ein Maß für die Streuung von Daten. Sie gibt an, in welchem Umfang erhobene Werte vom Durchschnittswert abweichen.
Zur Berechnung ziehen wir die Wurzel aus der Varianz.
Berechnung:

Die Standardabweichung beträgt 12.26 cm, d. h., dass die Körpergrößen durchschnittlich um 12.26 cm von der Durchschnittsgröße von 172 cm abweichen.
Spannweite
Die Spannweite ist der Abstand zwischen dem kleinsten und dem größten Wert des Datensatzes.
Zur Berechnung ziehen wir das Minimum eines Datensatzes vom Maximum ab.
Berechnung:

Die Spannweite liegt bei 35 cm, d. h., dass der Abstand zwischen der kleinsten und der größten befragten Person 26 cm beträgt.
Zusammenhangsmaße
Zusammenhangsmaße geben uns Auskunft über die Stärke (und in manchen Fällen zusätzlich über die Richtung) eines statistischen Zusammenhangs zwischen zwei Variablen.
Welches Zusammenhangsmaß du verwenden kannst, hängt vom Skalenniveau deiner Daten ab.
Zu den Kennzahlen des statistischen Zusammenhangs zählen
Korrelationskoeffizent nach Pearson
Um den Zusammenhang zwischen zwei metrischen Variablen anzugeben, bestimmen wir die Kovarianz und (daraus) den Korrelationskoeffizienten.
Beispiel:
Nehmen wir an, wir haben zusätzlich zu der Körpergröße auch das Gewicht der zehn Personen erhoben. Nun wollen wir den Zusammenhang zwischen den beiden Variablen “Körpergröße” und “Gewicht” bestimmen.
| Person | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Körpergröße in cm | 180 | 165 | 172 | 165 | 187 | 192 | 158 | 165 | 180 | 156 |
| Gewicht in kg | 75 | 60 | 70 | 65 | 85 | 90 | 57 | 58 | 65 | 53 |
Dazu berechnen wir zunächst die Kovarianz und erhalten ein Ergebnis von sxy= 136.44, was bedeutet, dass ein positiver Zusammenhang zwischen den beiden Variablen “Körpergröße und “Gewicht” besteht.
Im Artikel zur Kovarianz findest du eine Schritt-für-Schritt Anleitung zur Berechnung dieses Wertes.
Außerdem haben wir über die Formel der Standardabweichung folgende Werte bestimmt:
sx = 12.26 (für die Variable Körpergröße)
sy = 12.04 (für die Variable Gewicht)
Nun fügen wir die Kovarianz und die Standardabweichungen der beiden Variablen in die Formel zum Korrelationskoeffizienten ein:

Die Korrelation zwischen den beiden Variablen “Körpergröße” und “Gewicht” beträgt r = 0.92.
Rangkorrelationskoeffizient nach Spearman
Um den Zusammenhang zwischen zwei ordinalen Variablen anzugeben, bestimmen wir den Rangkorrelationskoeffizienten nach Spearman.
Beispiel:
Wir haben acht Studierende nach Ihren Abiturnoten in den Fächern Deutsch und Englisch gefragt und wollen nun den Zusammenhang zwischen den beiden Variablen bestimmen.
| Person | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Punkte in Deutsch | 14 | 8 | 11 | 6 | 15 | 13 | 7 | 9 |
| Punkte in Englisch | 11 | 15 | 8 | 10 | 13 | 12 | 9 | 14 |
Dazu berechnen wir den Rangkorrelationskoeffizienten und und erhalten einen Wert von ρ = 0.19.
Im Artikel zum Rangkorrelationskoeffizienten findest du auch eine Schritt-für-Schritt Anleitung zur Berechnung dieses Wertes.
Kontingenkoeffizient
Um den Zusammenhang zwischen zwei nominalen Variablen anzugeben, können wir den Chi-Quadrat-Wert und daraus Cramers V und den Kontingenzkoeffizienten bestimmen.
Beispiel:
Wir haben 250 Personen von drei verschiedenen Studienrichtungen, nämlich Jura, Naturwissenschaften (NW) und Sozialwissenschaften (SW) befragt und wollen nun den Zusammenhang zwischen der Wahl der Studienrichtung und dem Geschlecht der Studierenden bestimmen.
| Jura | NW | SW | Summe (Zeile) | |
|---|---|---|---|---|
| Weiblich | 38 | 35 | 57 | 130 |
| Männlich | 32 | 45 | 43 | 120 |
| Summe (Spalte) | 70 | 80 | 100 | 250 |
Dazu bestimmen wir zunächst den Chi-Quadrat-Wert und wandeln diesen dann in den Kontingenzkoeffizienten um.
In unserem Beispiel haben wir ein Chi-Quadrat von χ2 = 3.69.

Nun setzen wir den Chi-Quadrat-Wert von χ2 = 3.69 in die Formel zum Kontingenzkoeffizienten nach Pearson ein:

Anhand des Ergebnisses von KP = 0.17 können wir ablesen, dass es einen schwachen statistischen Zusammenhang zwischen den Variablen “Geschlecht” und “Studienrichtung” gibt.
Unterschied zwischen deskriptiver und induktiver Statistik
Der zentrale Unterschied besteht darin, dass wir in der deskriptiven Statistik ausschließlich Aussagen über unsere Daten treffen, während wir in der induktiven Statistik (auch Inferenzstatistik genannt) von Daten aus einer Stichprobe auf eine Grundgesamtheit schließen.
Tipp zur deskriptiven Statistik in deiner Abschlussarbeit
Im Ergebnisteil einer Bachelorarbeit oder Masterarbeit wird meist mit den deskriptiven Statistiken begonnen. So bekommen Lesende einen Überblick über die erhobenen Daten und die Stichprobe.
Im nächsten Schritt kannst du dann zu den Ergebnissen deiner statistischen Analysen und Signifikanztests übergehen.
Beispiel zur deskriptiven Statistik im Ergebnisteil
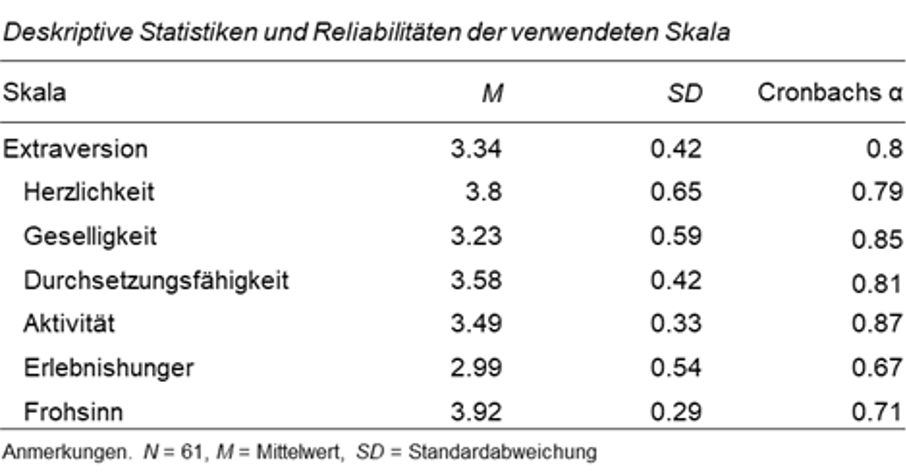
Nehmen wir an, wir haben die Variable Extraversion anhand unserer Stichprobe erhoben und stellen nun die Mittelwerte, Standardabweichungen und Reliabilitäten der einzelnen Facetten in einer Tabelle dar.
Die Tabelle zeigt dir ein Beispiel, wie du die deskriptiven Statistiken in deiner Abschlussarbeit übersichtlich darstellen kannst.
Häufig gestellte Fragen
Diesen Scribbr-Artikel zitieren
Wenn du diese Quelle zitieren möchtest, kannst du die Quellenangabe kopieren und einfügen oder auf die Schaltfläche „Diesen Artikel zitieren“ klicken, um die Quellenangabe automatisch zu unserem kostenlosen Zitier-Generator hinzuzufügen.
Benning, V. (2020, 20. August). Deskriptive Statistik verstehen und anwenden. Scribbr. Abgerufen am 14. April 2025, von https://www.scribbr.ch/statistik-ch/deskriptive-statistik/
